Mining Citation in Digital Humanities: a Central Bibliography of Digital Humanities Quarterly
This is the transcript of a five-minute “lightning talk” that I gave at the NULab & DSG Fall Welcome event at Northeastern University, on Sept. 26, 2017.
The visual aids were created by Julia Flanders.
Hi everyone! For those of you who may not know me, I’m Gregory Palermo. I currently serve as a Research Associate for the Digital Scholarship Group here in Snell Library. I’m also a Managing Editor of the scholarly journal Digital Humanities Quarterly, which is housed here at Northeastern.
From 2011-2014, with support from an NEH Digital Humanities Startup grant, DHQ began creating a centralized bibliographic resource. In this XML database, we sought to aggregate the bibliographies from all published DHQ articles. Up until now, each article has had its own bibliography. Every in-text citation in an article, which is encoded in a customization of the TEI markup language, points to an entry in the article’s bibliography. Each entry has an xml:id. Our managing editors mark up the author-provided bibliography, which our editorial process allows to vary in citation style. You can see an example of this here on the left.

We used the funds from our Startup grant to start development on a centralized and curated bibliography, which we have called Biblio, with its own set of defined elements. Its structure is more fine-grained and controlled than the individual articles’ encoded bibliographies. Right now, each entry in a bibliography uses a key attribute to point to a unique record in this central bibliography.
Earlier this year, DHQ Editor-in-chief Julia Flanders and I secured an NEH Digital Humanities Advancement Grant to continue developing Biblio. We hope, going forward, to have in-text citations point directly to Biblio, and to render published articles’ bibliographies from it. Since 40-60 DHQ articles are currently published each year, we’d like to get the data up to date, and keep them up to date. We will complete the existing prototype bibliography—adding two to three thousand additional backlog records to its existing six thousand—and establish editorial workflows in order to sustain it.
But, why bother? First, there are workflow advantages for our editorial staff. More importantly, the overarching goal of this project is to transform a one-off dataset to a sustainable resource for the DH community, opening up the archive of our open-access journal for citation analysis. Because DHQ targets a broad audience of digital humanists and computational social scientists, that archive is a rich resource for studying the field’s composition. Our corpus of articles represents a range of geographic and cultural differences, intellectual commitments, modes of scholarly engagement, and disciplinary practices.
Current work in digital humanities tracing strands of interest and influence in the field uses networks to visualize co-citation and bibliographic coupling. Here is an mockup, in terms of our data.
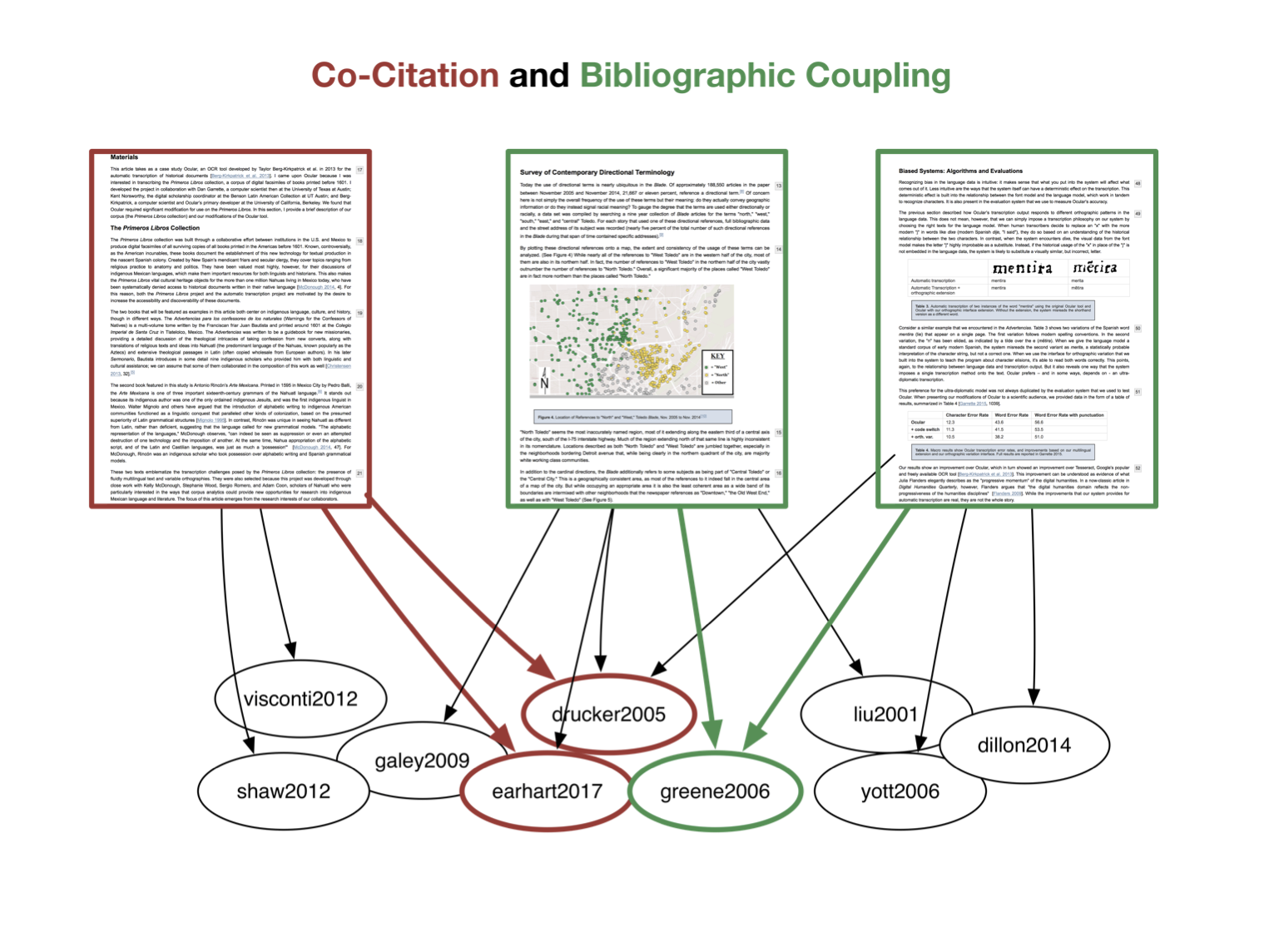
The center and right-hand articles both cite greene2006, so they are bibliographically coupled. Coupling offers us snapshots of the community at the time of publication. We might identify traditions of DH scholarship in articles that derive from common key influential sources. “drucker2005” and “earhart2017” are, alternatively, co-cited in the left-hand article. If they are also cited together elsewhere, we might conclude that they are related. As new articles are published that co-cite the same sources, co-citation offers us a picture of how the DH traditions perceived by our authors may be re-written over time. Together, these methods can be used to identify what in rhetoric we call communities of practice, such as subfields, and how they have changed as the field has come of age.
There is, however, untapped potential for Biblio, given that the resource is pointed to by the full, encoded text of all of our articles. We can mine their structures to ask new questions of rhetorical interest from the data. These include questions of purpose and execution—so, not just what, but why and how. Here are three examples of DHQ articles that use citation differently.
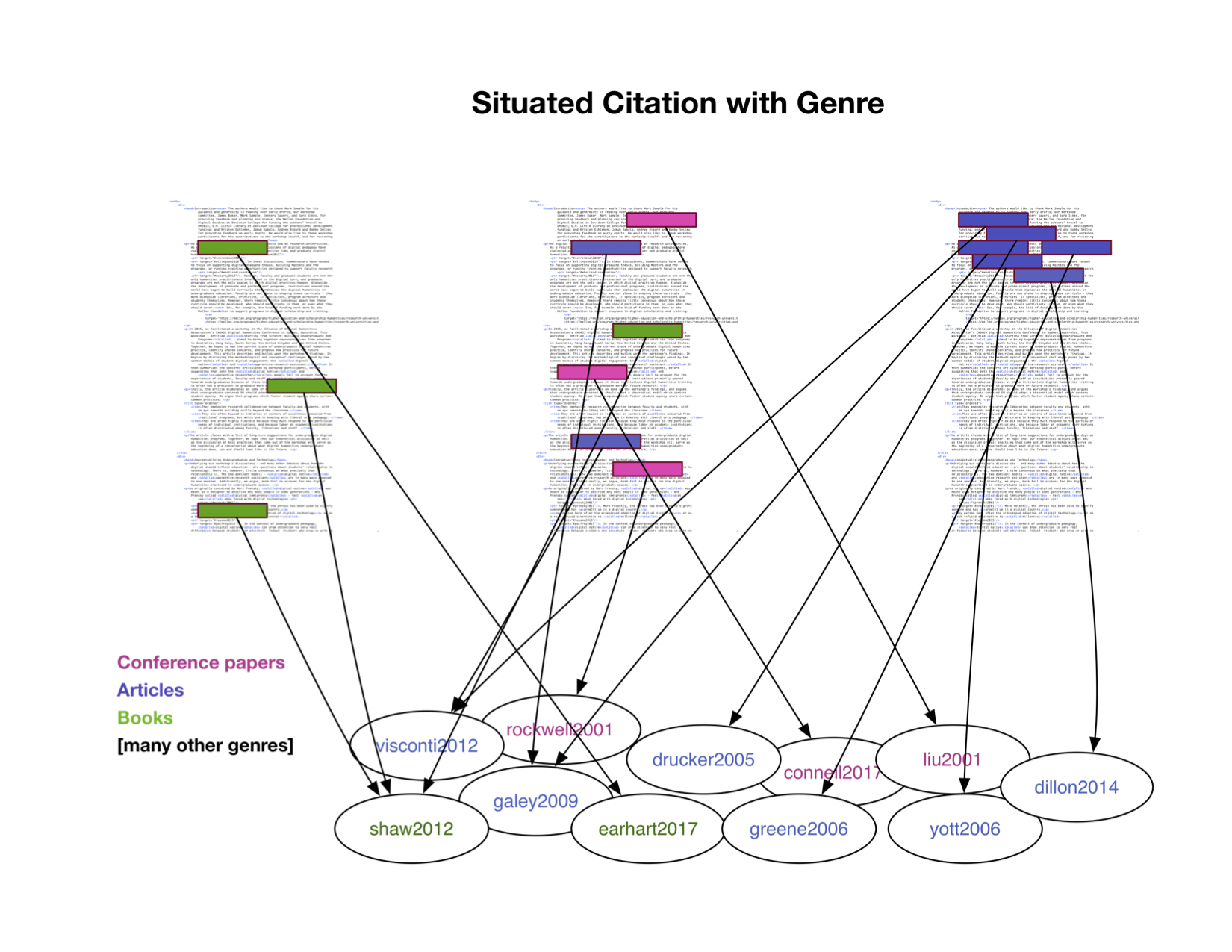
The article on the left invokes books in turn for sustained analysis, citing them sequentially. We might call this exegesis. On the right, we see a high density of cited articles, especially early in the article. This could be a literature review. In the middle, sources of multiple genres are threaded together and ventriloquized—my own frequent armature of choice.
Here are the exegesis and lit review examples zoomed in a bit.

Our pointer elements, which represent in-text citations, can be mined for citation proximity information, to quantify location and density. We can also distinguish between quoted and paraphrased text. We might be interested not only in what sources are frequently cited together, but if there are particular parts of those sources that crop up frequently. We might be interested in what purpose invoking a certain source most often serves in the articles of our corpus. We might be curious if any of these different practices cohere according to networks of co-citation, or according to our authors’ disciplinary backgrounds.
Julia and I are excited to get started on this work, which will commence in the Summer of 2018. If any of this seems interesting to you, or perhaps you have a background in bibliometrics, please don’t hesitate to contact her or myself. Thanks!